:::
科技新知

雲端大廠新AI模型對資訊硬體影響分析
發表日期:2024-06-26
作者:楊智傑(資策會)
摘要:
雲端大廠Meta和Google相繼於2024年4月及5月推出其新一代大語言AI模型,引發業界廣泛關注。
全文:
一、前言
雲端大廠Meta和Google相繼於2024年4月及5月推出其新一代大語言AI模型,引發業界廣泛關注。觀察Google推出的Gemini 1.5,及Meta推出的Llama 3大語言AI模型,除了宣示兩家大廠在大語言AI領域將持續和ChatGPT分庭抗禮,其背後所需的算力需求同時也對資訊硬體產業帶來新的契機。
二、事件背景
Google在2024年5月於Google I/O 2024大會上正式發布了Gemini 1.5模型,這一模型主要差異在於Google在多模態AI(Multimodal AI)和長上下文(Long Contex)理解方面的改良。Gemini 1.5 Pro特色在於能夠處理高達200萬個token的上下文訊息,這對於大型文本總結(140萬字)、大型影片(2小時)分析、大型程式碼(超過60,000行)分析及撰寫等任務具有實際效用。Gemini 1.5模型基礎有別於建立在單一大型神經網路的Transformer,而是以更小的「專家」神經網路群組,組成專家混合式(Mixture-of-Experts, MoE)模型。根據輸入的類型,MoE模型僅需選擇性發動最相關的專家路徑,無須載入整體參數,以此提升模型的推論效率。
此外,Google還從原本Gemini模型系列的Nano、Pro、Ultra外(模型大小由低至高),另外推出了從Gemini 1.5 Pro精簡的Flash版本,Gemini 1.5 Flash為一輕量化高效模型,專為需要高頻率、低延遲任務而較單純的AI應用設計,也是目前延遲最低的Gemini版本,對於需要即時應用的多模態AI情境(如雲端即時口譯)具應用潛能。
另一方面,Meta則在2024年4月10日於其官方網站技術部落格上公開發布了Llama 3大語言模型。Llama 3模型包括8B(80億參數)和70B(700億參數)兩個版本,相較於之前的Llama 2以及同等級大語言模型,在各種推論任務,包括MMLU(多任務語言理解能力)、AGIEval(AI生成問答能力)、ARC-Challenge(科學知識應用能力)等表現上皆有所提升。
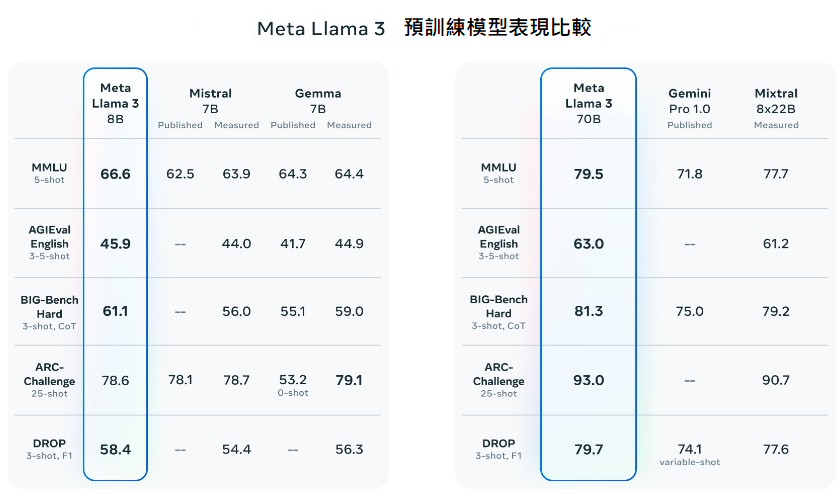
資料來源:Meta(2024/06)
圖1 Llama 3在各項任務表現中勝過同等級參數的模型
上述新模型的出現,除對百家爭鳴的大語言AI應用端開闢新的戰場,也對資訊硬體算力需求有所增加,除雲端大廠既有的GPU配置,包括Google TPU、Meta自研晶片的MTIA(Meta Training and Inference Accelerator)需求,以及相關伺服器布建,皆將帶動臺灣相關產業鏈商機,以下將從新模型對硬體需求進行評述。
三、Google、Meta新模型對資訊硬體運算需求提升分析
(一)Gemini1.5:更長的上下文窗口帶動加速器、記憶體需求
由於Gemini 1.5引入了較長的上下文窗口,相較於Gemini 1.0的上下文窗口僅32,000個Token,1.5版本在推論時需要的資源明顯增加:在較長的上下文窗口推論條件下,類神經模型需要預載更多的參數和進行更多次的矩陣運算,即使在Google的MoE分散式專家架構之下,對於處理器(如GPU或TPU)的需求預期仍會增加。此外,較長的上下文也意味著需要儲存更多的數據和中間運算成果,因此對記憶體的需求也會提升。為了處理基於雲端運算的Gemini 1.5大語言模型,可預期Google需要擴展其雲端運算基礎設施,包括TPU等高性能運算節點,來因應大規模的訓練和推理。
值得注意的是,Google官方並未透露Gemini 1.5的具體參數數量以及技術細節,然而從Gemini 1.5的MoE專家架構來看,每個獨立的專家模型都可能有其獨立的參數集(Parameter Set),而專家模型間亦會有共享參數,因此雖然MoE可以增加推論效率,然而在訓練與微調階段,可以推測將需要更多的運算資源進行MoE架構的訓練與建立。
(二)Llama 3:增加與使用者接觸面,提高未來總運算量需求
另一方面,Meta在2024年4月推出的Llama 3大語言模型,若單從參數量上來看,Llama 3與Llama 2在參數量上並無顯著差異(最高皆為80B),上下文窗口的長度也差距不大(長度由4,096增加至8,192 Token)。然而,除了Llama 3因訓練數據為Llama 2的7倍,而在推理上能有更好表現外,Llama 3也與Facebook、Instagram和WhatsApp上的Meta 聊天助理整合,相較於初代的Llama較屬於產學研究使用範疇的特性,Llama 3大幅增加了和使用者的接觸面,在策略上與微軟將其AI服務與其優勢的Office Suite整合類似,預計在使用者基數及流量擴大的狀況下,同步提升硬體運算需求。
此外,Meta也在2024年5月公布新的使用者條款,宣布將以社群上的使用者公開之內容,訓練其生成式AI模型(即Llama和其後續板本)和功能,由於Facebook、Instagram社群分別具有超過30億名用戶及20億名活躍用戶,持續產出海量影音內容於平台之上,預期將大幅擴增Meta未來生成式AI模型訓練時的算力和儲存需求。
四、對臺廠契機
在Google、Meta對算力需求提升下,國內資訊硬體供應鏈亦出現相關機會。Google於4月雲端大會推出的Tensor TPU V5,以及Google在5月Google I/O開發者大會宣布的TPU V6自研晶片,峰值運算效能比TPU V5e高出4.7倍的Trillium,皆預期將陸續於Google資料中心服役,除進行Gemini的訓練與推論外,亦已開始支援其他業者如Anthropic、Midjourney、Salesforce的AI模型雲端部署服務。在ASIC晶片設計方面,有機會持續帶動國內IP業者如世芯-KY、聯發科、以及臺灣伺服器組裝、伺服器關鍵零組件業者契機。
而Meta推出的Llama 3,則可預期會在Meta自家的新一代的自研晶片MTIA(Meta Training and Inference Accelerator)上進行運算優化,以進行更有效率的模型訓練與推論。而MTIA晶片的部分IP則與臺灣RISC-V晶片架構業者晶心科合作研發,因此臺灣RISC-V晶片出貨與相關研發量能亦可能提升。此外,在搭載MTIA的伺服器組裝上,未來亦有機會陸續帶動臺灣伺服器代工廠如廣達、緯穎業者出貨。
然而,相較於搭載ASIC的伺服器,目前NVIDIA的通用GPU(如H100、H200)在模型訓練上仍具備優勢,除了處理的任務類型更泛用,AI開發生態系也較完整,其推出周期亦較專用的ASIC為快速,因此雲端業者短期內並無全面替換為ASIC的可能性,例如AWS在2023年11月宣布自研ASIC Graviton新版本同時,也同時宣布與NVIDIA加強合作並將導入H200,因此從伺服器角度而言,雲端大廠拓展搭載ASIC的伺服器,對既有高階整體伺服器需求應無排擠效應之情形。
總體來看,除Google、Meta於近日發布新的大語言模型、AI ASIC之外,Microsoft也在2023年底首次亮相自研AI晶片Athena,AWS也於2023年底推出Graviton 4和Trainium 2訓練晶片,大型雲端業者皆希望藉由自研ASIC降低對NVIDIA GPU的依賴,並搭配自身AI模型、基礎環境進行成本效益最佳化的AI服務,從晶片端而言,更多ASIC中各元件的設計需求,對我國IP設計業者帶將來契機。
五、結論
2024年Google推出Gemini 1.5和Meta的Llama 3模型,分別代表雲端大廠在多模態AI長上下文理解、以及擴增使用者群落的重大突破。Gemini 1.5由於能夠處理高達200萬個token的上下文訊息,對於大型文本總結、長影片分析和大型程式碼專案撰寫等任務,開始具有應用潛力。而Llama 3在推理任務上的表現提升、與Meta既有社群服務的介接,則展示了Meta在增強AI模型實用性和使用者體驗上的進展。
上述模型的出現,意味著雲端大廠對加速晶片和記憶體需求的增加。預計Google為此需要擴展其雲端運算基礎設施,以支持大規模的訓練和推理任務,除高階GPU伺服器外,對於自家TPU建置的步調將會提升。而Meta的Llama 3在與Facebook、Instagram上的整合,將提高模型的實際應用範圍,而Meta納入Facebook等社群使用者數據做為訓練來源,也將進一步增加其硬體運算、儲存需求。
對於臺灣的資訊硬體供應鏈來說,雲端業者發展的大語言AI也來了新契機。Google和Meta對高性能運算設備的需求,使其加速自研ASIC腳步,並使臺灣的IP業者和RISC-V晶片廠商也在這波技術變革中受惠,而搭載ASIC的伺服器因暫未可能取代GPU伺服器,因此對伺服器業者而言亦無替代效應之情形發生,可視為正面契機。
(本文作者為資策會MIC執行產業技術基磐研究與知識服務計畫產業分析師)
 點閱數
點閱數:
432
