:::
科技新知

國際大型語言模型應用技術觀測
發表日期:2023-06-21
作者:王允中(工研院)
摘要:
大型語言模型的發展潛力受各大國際企業與組織重視,並相繼投入開發與投資。本文以Microsoft、Google與Amazon等國際標竿廠商近期於大型語言模型的發展動態為例,介紹將大型語言模型技術轉化為產品服務與解決方案。
全文:
一、大型語言模型技術發展
大型語言模型(Large language model, LLM)為人工智慧(Artificial Intelligence, AI)技術之一,旨在處理和理解大量自然語言資料。2017年Google提出Transformer模型架構論文,並於2018年推出基於Transformer架構的語言模型BERT(Bidirectional Encoder Representations from Transformers),以無監督的方式處理大量無標註文本,其理解上下文的自注意力機制(Self Attention)以及兩階段遷移學習(Transfer Learning)的應用,成為諸多大型語言模型開發研究與改進的基礎,推動大型語言模型技術發展不斷進步。2022年11月底Open AI發布基於大型語言模型的聊天機器人ChatGPT(Chat Generative Pre-trained Transformer),主要功能可問答、編寫故事或代寫程式碼等,此大型語言模型的應用帶動AI新一波熱潮,ChatGPT於5天內突破百萬註冊人數,並於兩個月使用人次破億。Meta亦於2023年2月發布其大型語言模型LLaMA(Large Language Model Meta AI),Google於2023年3月發布基於大型語言模型LaMDA(Language Models for Dialog Applications)的聊天機器人Brad,Amazon也在2023年4月加入大型語言模型競賽,發布其大型語言模型Titan以及雲端服務Amazon Bedrock協助用戶開發AI服務,國際大型企業與組織相繼投入模型開發與相關研究,以下介紹大型語言模型的技術重點。
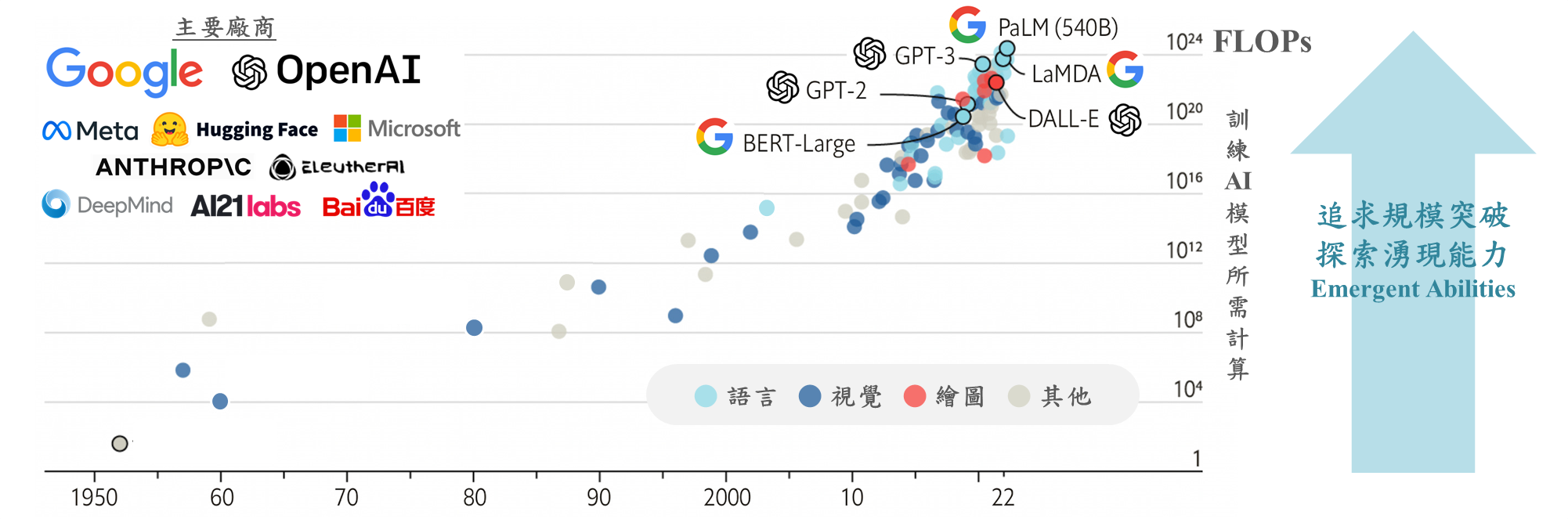
資料來源:工研院產科國際所 ITIS研究團隊(2023/06)
圖1 大型語言模型發展與主要廠商
(一)大型語言模型的湧現能力(Emergent Abilities)
大型語言模型的性能表現與其規模大小有密切關聯,2022年10月發布的論文「Emergent Abilities of LLM」研究不同規模大小的模型對於各種任務的表現能力,發現當模型突破某個規模的臨界值後,各種任務的表現皆大幅度提升,此彷彿「頓悟」的表現即為大型語言模型的「湧現能力」現象。2022年10月Google發布其大型語言模型PaLM(Pathways Language Model)的論文,比較不同參數量的PaLM模型版本對於各種任務的表現能力,發現參數量最大的版本具有顯著優勢,模型的擴展改進尚未達到飽和點,繼續增加模型大小可提升表現能力。研究也觀察到在部分任務中,準確度並不是等距成長,而是在參數量最大的模型中準確率急劇上升,顯示當模型達到足夠的規模時,大型語言模型的新功能就會湧現,且此現象可能隨規模擴大繼續發生,並超出當前研究的規模。大型語言模型「能力不存在於較小的模型中,但存在於較大的模型中」的特徵,讓研究與開發方向朝向對更大規模的探索,也是國際大型企業與組織相繼投入的原因之一。
(二)大型語言模型的資源需求與效率提升
模型規模擴展將伴隨著訓練模型的所需時間增加、運算資源與能源成本也大幅提升,以訓練Open AI的大型語言模型GPT-3為例,訓練約需花費數百萬美元,如果使用運算速度全球排名第一名的美國國家實驗室超級電腦Frontier訓練模型約需要歷時3.3天,使用排名第十名的法國超級電腦Adastra訓練模型約需要歷時79天,而排名百名的美國超級電腦Sawtooth訓練模型約需要歷時729天。龐大的訓練成本使大型語言模型通常只會訓練一次,且僅少數大型企業可負擔,模型訓練成果是否實現該模型規模可帶來的最佳表現成為重要的課題。DeepMind於2022年5月發表的論文探討訓練的模型大小和其所需的資料量(tokens標記數量),發現模型大小和訓練資料量應按比例同步增加,方可實現其最佳表現,指出當前多數的大型語言模型規模雖大,但訓練資料明顯不足。企業在開發模型時可考慮依照擁有的資料量開發夠用的模型大小,可節省訓練成本並取得較佳的模型表現能力。除了資料量的考量,優化模型也是可降低運算需求的研究方向,Google於2023年2月分享其近一年在高效深度學習算法的研究成果,包含高效架構(如上下文增強模型和專家混合模型)、訓練效率(如模型裁剪和隨機梯度下降方法)、數據效率(如採樣權重優化)和推理效率(如知識蒸餾和自適應計算優化)等方面的研究,提供追求模型規模以外的發展方向,降低運算需求的限制因素,加速AI應用普及。
(三)大型語言模型的認知能力提升與幻覺現象(Hallucination)
大型語言模型的認知能力近年大幅提升,以Open AI於2023年3月發表的大型語言模型GPT-4為例,其學術表現能力已可通過模擬律師考試,且分數落在應試者的前10%。然而目前實務上表現的正確率尚有很大的進步空間,以ChatGPT的回答表現為例,其回答無法「一定正確」或「一定不正確」,而是「不一定正確」,由於文句通順且回答完整而讓使用者難以辨識真假,當不清楚事實時,很容易被AI「一本正經地胡說八道」而誤導。當AI在無法找到準確答案時,卻自信地回答其編造的錯誤資訊,此反應被稱為「幻覺」現象。大型語言模型通常使用公開資料(如網路資料)進行訓練,也導致資料庫中涵蓋正確和錯誤的解決方案並存(如數學解題)、自相矛盾的陳述、各式各樣的意識形態和想法。當用戶向模型提問時,模型須能理解用戶的意圖,並做出合適的回應。OpenAI運用基於「人工回饋的強化學習(Reinforcement Learning from Human Feedback, RLHF)」微調模型的方式,透過標記人員的反饋調教模型,為模型的回答作評分,讓模型調整各種可能選項的回答機率,直到輸出的結果是符合標記人員所認可的標準。藉此機制標記不正確的答覆,持續改進事實準確度與模型認知能力,緩解幻覺現象,初步成效已於GPT-4模型中展現,其產生事實答案的可能性比GPT-3.5模型提升40%,偏差與有害輸出也大幅降低。
二、國際大型語言模型標竿廠商
大型語言模型的發展潛力受各大國際企業與組織重視,並相繼投入開發與投資。本文以Microsoft、Google與Amazon等國際標竿廠商近期於大型語言模型的發展動態為例,介紹將大型語言模型技術轉化為產品服務與解決方案。

資料來源:工研院產科國際所 ITIS研究團隊(2023/06)
圖2 Microsoft、Google、Amazon發展與解決方案
(一)Microsoft
Microsoft於2019年7月投資OpenAI十億美元,成為OpenAI的獨家雲端運算服務提供商,OpenAI為美國AI新創,自2016年成立以來開發GPT系列大型語言模型與ChatGPT、DALL-E2生成式AI算圖應用服務。Microsoft於2021年11月推出Azure OpenAI服務,協助企業部署大型AI模型與應用服務,2023年1月再次投資數十億美元,擴大與OpenAI的合作夥伴關係,Microsoft將基於GPT-4模型的自然語言對話式服務及生成式服務加入Bing瀏覽器,成為以對話形式呈現的AI支援搜索引擎,也整合至辦公軟體成為Microsoft 365 Copilot,開發出文檔初稿撰寫、回覆文件生成、資料SWOT分析、簡報製作等AI支援功能,運用AI將重複性、庶務性工作自動化並提供智慧分析建議,將大型語言模型技術轉化為服務解決方案,Microsoft與OpenAI的合作在這一波大型語言模型與生成式AI的快速發展中取得先機。
(二)Google
2023年2月Google運用其大型語言模型與生成式AI相關技術,包含大型語言模型LaMDA和PaLM、文字轉圖像模型Imagen和文字產生音樂模型MusicLM的基礎上,開發對話式AI服務Bard,具備問答、草擬文章、整理會議待辦事項、生成程式碼等AI支援功能。2023年3月Google在其全託管機器學習平台Vertex AI推出生成式AI應用程式建置工具,方便資料科學家存取基礎模型與開發具有生成式AI功能的應用程式。2023年4月宣布將旗下兩個主要的AI研究部門Brain和DeepMind合併為Google DeepMind,整合AI研發成果包括圍棋模型AlphaGo、Transformer、文字表示模型word2vec、音訊波形深度生成模型WaveNet、蛋白質結構預測模型AlphaFold、深度強化學習、分散式系統及訓練部署大型AI模型的軟體框架,藉由整合研究能量加速Google在AI的技術發展。
(三)Amazon
Amazon於2023年4月發布其大型語言模型Titan以及雲端服務Amazon Bedrock協助用戶開發AI服務,Amazon加入大型語言模型競賽的策略,不是完全自行構建AI模型,而是招募第三方在其雲端運算服務平台AWS(Amazon Web Services)託管模型。Amazon Bedrock協助用戶使用AI21 Labs、Anthropic、Stability AI等AI新創公司的預訓練模型構建生成式AI驅動的應用程式,AI21 Labs Jurassic-2大型語言模型可運用於生成多語言文本,Anthropic Claude大型語言模型可運用於對話和文本處理任務,Stable Diffusion AI算圖服務可從文本生成藝術作品和圖形設計。此外,AWS也和機器學習共享平台Hugging Face擴大合作大型語言模型和生成式AI應用程式的訓練部署,支持自然語言處理、電腦視覺及音訊處理等各種任務的模型,開發人員可使用AWS工具優化模型性能。
三、結論
ChatGPT的推出席捲全球,大型語言模型的應用帶動AI新一波熱潮,國際大型企業一方面加強研究大型語言模型規模與性能的突破,同時也加緊步伐將技術轉化為產品與解決方案。大型語言模型的發展加速大量且多元的資料持續生成累積,AI演算法和軟硬整合的AI運作系統同步精進,隨著各大企業的大型語言模型的開發平台推出,將帶動企業與新創開發更多元的應用服務。另一方面,當前大型語言模型在其仍存在AI幻覺弊病的情況下,快速走入社會大眾的工作與日常生活中,也引發科技亂象與社會議題的討論,包括資訊真偽與濫用於大規模散佈假消息的風險、演算法的偏見、AI生成資料的正確性、模型安全與隱私保護等問題。各國政府加強對AI的重視程度,除了加大國家AI研究發展預算與建設支持大型語言模型運算需求的基礎設施,也公布AI相關政策以監管運用AI技術之相關產品與應用服務,運用AI活絡產業創新轉型,並控管運用AI的風險,發展值得信任的AI科技。
(本文作者為工研院產科國際所執行產業技術基磐研究與知識服務計畫產業分析師)
 點閱數
點閱數:
1789
